
Voici un petit article raspberry sur l’AEC, la réduction de bruit, et pourquoi il ne faut pas s’attendre à de la magie du ReSpeaker Mic Array v2. Attention, qu’on se comprenne bien, il est performant lorsqu’il est utilisé comme il est censé être utilisé. C’est juste que je lis pas mal de posts sur les forums où les utilisateurs sont déçus car ils s’attendaient à un truc magique.
La théorie
Alors avant de passer à la pratique, on va commencer par un peu de théorie histoire d’éclaircir un peu tout ça.
AEC
Qu’est ce que l’AEC ? Cela veut dire Accoustic Echo Cancellation, en bon français, annulation d’écho acoustique.
L’AEC permet de supprimer ce qui sort du haut parleur de ce qui rentre dans le micro. En gros, j’ai de la musique qui sort par le haut parleur, je parle dans le micro, qu’est ce qui se passe ? Le micro enregistre ma voix ET la musique. L’AEC consiste à supprimer la musique pour qu’il ne reste que ma voix. Ce qui est un peu ce qu’on cherche avec un assistant personnel.
Il y a un autre cas aussi très connu où on utilise l’AEC sans le savoir. Quand on fait de la téléphonie ou de la visioconférence ! Car sinon, la personne qui est de l’autre côté de l’écran, va entendre en retour sa propre voix passer par ton micro, et voir même repasser dans son micro et ressortir par ton haut parleur et re-rentrer dans ton micro etc… C’est ce qui provoque un écho qui peut parfois monter, monter et monter ! Jusqu’à ce qu’il y en ait 1 qui finisse par couper son micro.
Quand tu mets ton téléphone portable en haut parleur, il y a de l’AEC d’activé.
Voici un petit dessin qui expliquera peut-être mieux ce qui se passe sans AEC :
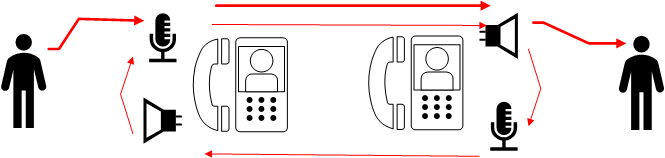
On voit bien qu’il y a une partie de ce qui sort du haut parleur qui est capté par le micro de l’interlocuteur. Ça revient donc dans le haut parleur de la personne de gauche, et ça re-rentre etc. Et du coup, ça provoque un écho.
Hé bien l’AEC, c’est ça :
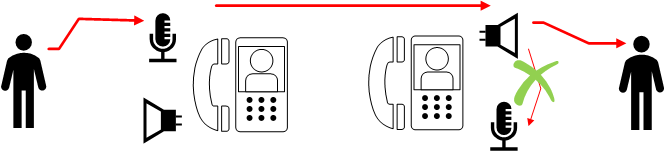
On va essayer de supprimer le son qui sort du haut parleur du son qui est entré par le micro.
Et comment on fait ça ? Alors, on va commencer par donner un exemple mais avec des couleurs. Imaginons que ce qui sort du haut parleur est de couleur rouge. Imaginons que ce qui sort de la bouche de l’interlocuteur est jaune. Ce qui rentre dans le micro est rouge (HP) et jaune (voix) donc orange. La seule chose que capte le micro c’est de l’orange. Donc notre micro envoie de l’orange
Mais n’oublions pas que notre super machine de visioconférence, elle sait que ce qui sort du haut parleur est rouge. Donc, si notre machine de visioconférence retire le rouge (HP) de l’orange (micro), alors il n’est censé rester que le jaune (voix).
Hé bien, l’AEC, dans l’idée c’est la même chose mais avec le son. Si notre visio connait le son qu’elle fait sortir du haut parleur, elle va essayer de l’enlever du son qui rentre par le micro.
Mais ce n’est pas si simple, car on va rencontrer plusieurs problèmes.
notion de temps
Le premier c’est que lorsqu’on parle de fréquence il y a une notion de temps qui rentre en jeux. Prenons une onde qui représente ce qui sort du haut parleur :
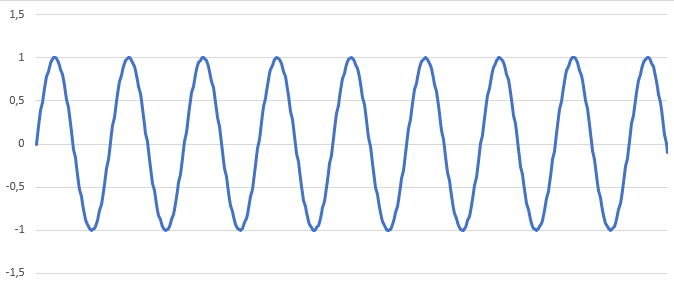
Je rajoute par-dessus l’onde qui représente ma voix.
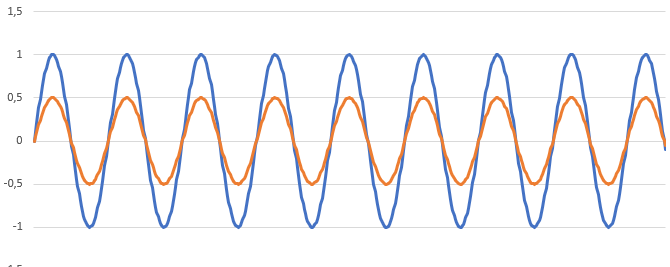
Ce que capte mon micro est donc la somme des 2 :
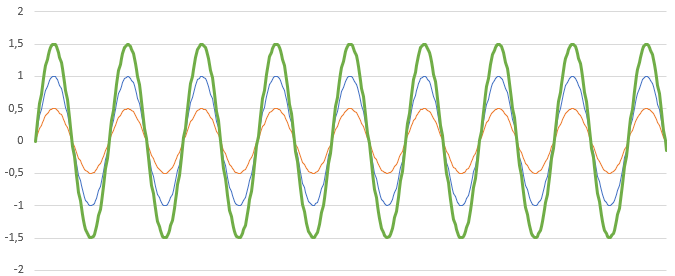
Dans l’idéal, ce que capte mon micro est donc le son vert.
Mais comme je l’ai dit plus haut, il y a une notion de temps. Le son va à 340 mètre par seconde. S’il y a environ 1m entre le micro et le haut parleur, le son va arriver au niveau du micro environ 3ms (0,003 seconde) plus tard. Donc, quand le son enregistré par le micro arrive à notre machine visio, ce n’est pas celui qu’elle en train d’envoyer au haut parleur, mais celui d’il y a 3 ms. Or elle, elle va chercher à annuler le son à l’instant T et non le son d’il y a 3 ms. Et à ça se rajoute le temps pris par la machine. Pour simplifier le problème, je vais juste décaler d’une chouille ma fréquence bleue.
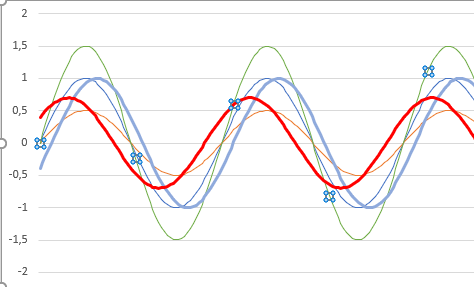
Le son bleu en gras, c’est le son décalé et celui qui va être utilisé pour “retrouver le son de la voix”. Donc si je prends le son vert, et que je lui retire mon nouveau son bleu, hé bien j’obtiens un son rouge. Et comme tu peux le constater, le son rouge n’est pas vraiment comme le son orange qui est réellement le son sorti de la bouche.
Maintenant, imagine que le son ne va pas directement du haut parleur vers le micro, mais rebondisse sur le mur derrière toi. Cela va accentuer encore un peu plus le retard.
Bon, en vrai, ce n’est pas exactement ça qui se passe, mais c’est surtout pour expliquer qu’il y a un “retard” de traitement qui doit être pris en compte.
Différence entre ce qui sort et ce qui rentre
L’autre problème, c’est que notre machine visio envoie un signal au haut parleur, et c’est tout ce qu’elle connait ! Après, il y a réellement ce qui va sortir du haut parleur.
Si tu prends un petit haut parleur USB acheté sur wish et un ampli avec enceinte pour audiophile… Il va y avoir une sacrée différence. Et ça, ta machine visio ne le sait pas ! Donc le son que va enregistrer le micro, une fois transformé en fréquence “réelle” par le haut parleur, ne correspondra pas totalement au son que pense envoyer la machine visio. Avec une super enceinte de qualité, ça ira, mais avec ton enceinte usb à 2 euros, ça ne sera pas la même chose.
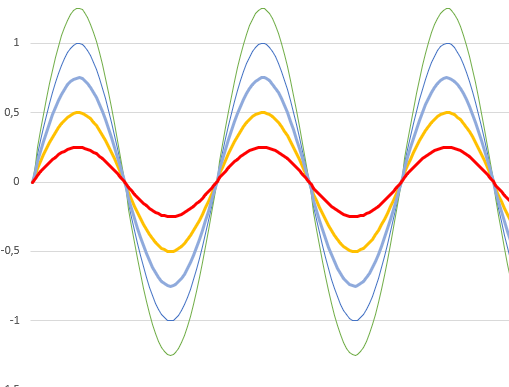
Alors en bleu fin, c’est ce que pense la machine visio en sortie de haut parleur. En bleu gras, c’est ce qui rentre dans le micro en provenance du haut parleur. On constate déjà, que ce n’est pas tout à fait la même chose. En vert, c’est la somme de la voix enregistrée par le micro (orange) et de ce qui sort du haut parleur (bleu gras). Et en rouge, c’est ce qui est enregistré par le micro (vert ou orange + bleu gras) de laquelle notre machine visio retire ce qu’elle pense qui sort du haut parleur (bleu fin). Donc le rouge c’est ce que notre machine visio pense être uniquement la voix.
On constate là encore que la courbe rouge et la courbe orange ne correspondent pas exactement.
Alors, de nouveau, ce n’est pas exactement ce qui passe, mais c’est pour expliquer qu’il n’est pas possible d’avoir une annulation exacte de l’écho.
Le bruit ambiant
Le dernier point qui gène l’AEC, c’est le bruit que ne connait pas notre machine visio.
Tous les sons qui ne viennent pas de la machine visio, celle-ci ne les connait pas et ne peut donc pas les annuler. Si tu as un camion de pompier qui passe sirènes hurlantes dans la rue, le micro va le capter. Mais la machine visio ne pourra jamais l’annuler puisqu’elle n’en a pas connaissance. Le léger souffle que va faire le haut parleur pourra aussi être capté par le micro. Le micro lui-même peut générer un souffle etc.
Du coup, si on veut supprimer ça, ce n’est pas avec l’AEC qu’on va y arriver.
Et après l’annulation ?
Comme on l’a vu plus haut, l’AEC ne peut essayer de supprimer que ce que la machine visio connait. Et le problème, c’est qu’en supprimant du son, elle va aussi un peu supprimer un petit peu de notre voix.
En fait, contrairement aux schémas qui sont un peu plus haut, le son, ça ne s’additionne pas et ne se soustrait pas comme des bonbons. Ce n’est pas si simple. Donc, en “supprimant” l’écho, on va rendre la voix d’un peu moins bonne “qualité”. Il va y avoir un peu de perte. Donc de l’AEC oui, mais attention de ne pas faire n’importe quoi non plus dans les réglages…
La réduction de bruit (Noise Reduction)
Donc on a vu plus haut que l’AEC supprime ce qui sort du haut parleur de ce qui rentre dans le micro.
Mais comment fait-on pour essayer de supprimer le bruit ambiant ? Hé bien il y a des algorithmes pour ça. Il y a des bruits ambiants qu’on connait et qu’on peut enlever comme un souffle, le brouhaha d’une gare ou d’un aéroport etc…
En fait, on va utiliser un peu la même méthode, c’est à dire qu’on va chercher à enlever du son de ce qui est capté par notre micro. Mais comment connait-on le son à enlever ? Ah !!! Tout est dans cette question. Et il y a plusieurs réponses possibles.
Ce qu’il faut savoir c’est que la voix, ce sont des fréquences que l’on connait. Donc, tout ce qui peut être en dehors de ces fréquences, hop ! on enlève. il y a par exemple les filtres passe haut. Ce paramètre existe sur le respeaker Mic Array v2.
On peut aussi enlever des bruits qu’on connait comme un souffle continu.
Il y a aussi la méthode d’utiliser la détection des moments où il n y a pas de voix. On enregistre alors ce son, considéré alors comme bruit ambiant. Et on l’enlève quand il y a de la voix.
Et encore tout un tas d’autres algorithmes qui utilisent tout un tas de formules mathématiques hors de ma portée.
L’AEC et le NR, ça marche bien ?
Hé bien ça dépend. Alors, évidemment, ça dépend, ça dépasse 😀 . En fait, généralement, plus on a de puissance de calcul et plus on peut appliquer d’algorithmes complexes et donc avoir un résultat optimal.
Et c’est bien le problème avec le raspberry. Si le CPU doit faire l’AEC et la réduction de bruit, ça va pas mal consommer de temps de calcul…
L’autre problème c’est que lorsqu’on fait de la réduction de bruit, il y a forcément une distorsion de la voix qui apparait. Car on va couper/réduire des fréquences, en faire ressortir d’autres etc. Et ça peut être gênant pour notre assistant personnel. Par exemple, pour kaldi, les développeurs déconseillent d’utiliser ce genre d’algo car ils estiment que généralement, cela rend la compréhension plus difficile par la machine.
De plus, les reconnaissances vocales récentes utilisent généralement le machine learning pour l’entrainement. Elles sont donc, dans la limite du raisonnable, capable de distinguer une voix dans un bruit ambiant. Mais si avec notre AEC et/ou NR, on génère trop de distorsion, alors la reconnaissance vocale fonctionnera moins bien car elle n’aura pas été entrainée sur une voix avec de la distorsion.
Mais de façon générale, attention aux réglages ! Une réduction de bruit trop agressive rendra le résultat de la voix encore moins compréhensible qu’avant.
En résumé
L’AEC ne peut essayer de supprimer que le son qu’il connait. Il ne supprimera pas les bruits de tondeuse du voisin un samedi après midi. Et encore moins le son de ta télévision !
Donc oui, si ton assistant personnel est à côté de la télé et qu’en plus tu regardes le journal télé (donc des voix), cela posera soucis.
Donc :
Non, l’AEC ne supprimera pas ce son et oui cela posera des problèmes pour la reconnaissance vocale (speech to text).
Oui, si tu te trouves à 10m, le son de ta voix sera faible et une fois l’AEC et éventuellement le NR appliqué, il ne restera plus grand à la reconnaissance vocale pour faire son travail.
Il n y a pas de magie.
Après, tu peux essayer de mettre un micro pile poil en direction de la télé et d’enlever ce qui vient de ce micro à ce qui est capté par le micro réservé pour la réception de la reconnaissance vocale. Mais là, il y a du taff 😀
Si tu veux avoir une vision plus juste scientifiquement parlant, je te conseille ces PDF :
http://documents.irevues.inist.fr/bitstream/handle/2042/12218/AR11_4.pdf?sequence=1
Bonjour cedcox,
Merci beaucoup pour tes guides très détaillés et qui plus est : écrits de manière sympa et ludique !
Tu parles de temps en temps du respeaker core v2. J’en ai un en ma possession et je ne demandais si je pouvais avoir un avis dessus ?
Il semble déjà plus musclé que le respeaker mic array, mais aussi équipe de plus de places dédiées au traitement de la voix (aec, doa, ns, wakeword, etc…)
Que penses-tu de la bestiole ?
J’aimerai tirer meilleur parti de ses capacités mais je ne sais pas trop par où commencer.
Installer rhasspy dessus ou bien se baser sur respeakerd et dialoguer avec l’api rhasspy ?
Comme tu le vois c’est un peu flou pour moi ^^
En ce moment je l’utilise comme satellite rhasspy mais j’ai l’impression qu’on peut mieux faire
Une idée ?
Merci d’avance et merci pour tes guides !
Jérôme
Bonjour Jerôme,
Le respeaker core v2 est plus complet parce qu’il contient déjà de quoi faire tourner le système d’exploitation. C’est un “tout-en-un” qui regroupe un raspberry et un mic array v2 qui n’est qu’une carte son en quelque sorte.
Après, je ne connais pas les caractéristiques techniques exactes du core v2, mais je pense que ça doit se rapprocher des mêmes composants que le mic array.
Donc pour tes questions, je n’ai pas d’idées ou de piste pour un cas qui marchera mieux qu’un autre. Certainement les essayer 🙂
Ced